kaggle-波士頓房價預測

一間房子到底要賣多少錢才符合行情?我們最直接想到的判斷要素應該會是這個房子的地段和坪數。實際上不只這兩點,還有許多因素會影響房價。我們就用kaggle上的波士頓房價資料集來看這件事吧
在資料前處理的部分我會
- 將資料視覺化,並對資料做一些轉換和剔除不重要或互相有強烈關聯的feature
- 了解各feature代表的意義,適當的填入缺失值和做one-hot coding
- 用Lasso做feature selection
接著進入training 的環節,我使用的model是XGBoost,以5-fold cross validation選出模型合適參數,最後用train出來的模型做房價預測
首先匯入套件和training, testing data set
#load module, data
import pandas as pd
import numpy as np
import sklearn as sci
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as stats
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LassoCV
from sklearn.feature_selection import SelectFromModel
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
Data Cleaning:
我將training和testing data的feature先合併以利接下來做統一處理,除了方便外也可以避免分開做歸一化會有尺度不相同的問題
dtrain=train.drop(['SalePrice'],axis=1)
database=pd.concat([dtrain,test])
首先我大致將資料分為’object_type’(qualitative)和’numerical_type’(quantative)
而由官網中data_description檔案對各feature的細節描述,
https://drive.google.com/file/d/17sT4kM4qbzHlQ9zO-V1ZK81Gdlm8YVQ6/view?usp=sharing
可以得知feature ‘MSSubClass’中的整數事實上是代表房屋交易的不同類別,並且數字大小和他的實際意義完全沒有關係,所以要把他的資料類別改成字串
#datacleaning
realobj=['MSSubClass']
database[realobj]=database[realobj].astype(str)
quant = [f for f in database.columns if database.dtypes[f] != 'object']
quali = [f for f in database.columns if database.dtypes[f] == 'object']
判定其中存在缺失的column為
Index([**'TotalBsmtSF', 'GarageArea', 'GarageCars'**, 'KitchenQual', 'Electrical',
**'BsmtUnfSF', 'BsmtFinSF2', 'BsmtFinSF1'**, 'SaleType', 'Exterior1st',
'Exterior2nd', 'Functional', 'Utilities', **'BsmtHalfBath',
'BsmtFullBath'**, 'MSZoning', **'MasVnrArea'**, '**MasVnrType'**, '**BsmtFinType1**',
'**BsmtFinType2**', '**BsmtQual**', '**BsmtCond**', '**BsmtExposure**', '**GarageType**',
'**GarageCond**', '**GarageQual**', '**GarageYrBlt**', '**GarageFinish**',
'LotFrontage', '**FireplaceQu**', **'Fence', 'Alley**', **'MiscFeature'**,
'**PoolQC**']
某些feature中的’NA’代表本身無該項feature,但pandas會把他判定成資料有缺失,對於這類feature ‘object_type’要置換成type-’None’,’numerical_type’要補零,比如’Pool QC’ (Pool Quality)的’NA’值代表沒有泳池,把NA改成’None’即可,其餘的缺失值’object_type’用該column的眾數補上,’numerical_type’則用該column平均值補上
non=['PoolQC', 'MiscFeature', 'Alley', 'Fence', 'FireplaceQu', 'GarageCond', 'GarageQual',
'GarageFinish', 'GarageType', 'BsmtCond', 'BsmtExposure', 'BsmtQual', 'BsmtFinType1',
'BsmtFinType2','MasVnrType']
zerof=['TotalBsmtSF', 'GarageArea', 'GarageCars','BsmtUnfSF', 'BsmtFinSF2', 'BsmtFinSF1','BsmtHalfBath',
'BsmtFullBath','MasVnrArea']
needfill=['KitchenQual','Electrical','SaleType','Exterior1st','Exterior2nd','Functional', 'Utilities','MSZoning']#front: numerical_type_feature backw: objective_type_feature
front=database[quant]
front[zerof]=front[zerof].fillna(0)
front['LotFrontage']=front['LotFrontage'].fillna(front['LotFrontage'].mean())backw=database[quali]
for x in needfill:
backw[x]=backw[x].fillna(backw[x].mode()[0])
backw[non]=backw[non].fillna('None')
視覺化各統計資料:
‘numerical_type_feature’數值分佈圖
c= [f for f in database.columns if database.dtypes[f] != 'object']
c.remove('Id')
f = pd.melt(front, value_vars=c)
g = sns.FacetGrid(f, col="variable", col_wrap=4 , sharex=False, sharey=False)
g = g.map(sns.distplot, "value")
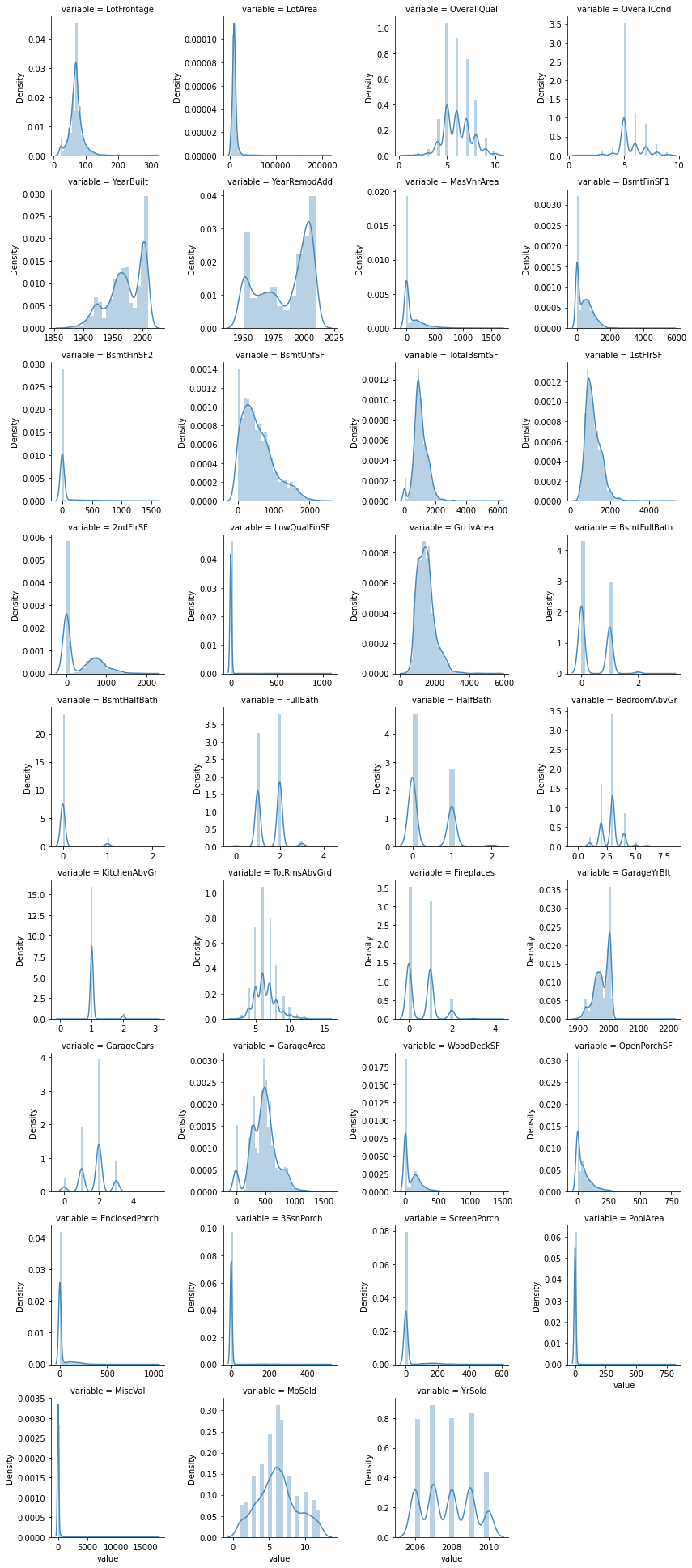
在這些分佈圖中,我們可以看出’LotFrontage’, ‘LotArea’ ,’1stFlrSF’ ,’GrLivArea’的分佈較接近log normal distribution,因此可以先將這些column的數值取log,使資料的分佈接近常態分佈,接著再對所有numerical_type_feature做normalization
另外’BsmtFinSF2’, ‘LowQualFinSF’, ‘BsmtHalfBath’, ‘KitchenAbvGr’, ‘EnclosedPorch’, ‘3SsnPorch’, ‘ScreenPorch’, ‘PoolArea’, ‘MiscVal’值非常集中且單一,無法從中得到資訊,可納入刪除名單
logtran=['LotFrontage','LotArea','1stFlrSF','GrLivArea']
front[logtran]=np.log(front[logtran])
front=(front-front.mean())/(front.std())
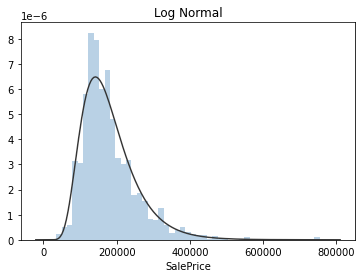
觀察Sale Price的數據,會發現它的分布是比較偏斜的,這樣的資料不利於Training,因為預測結果大量集中在某個區間範圍除了可能會讓機器忽略其他較離散的數值,也會讓機器較難分辨出不同feature對應到的不同預測值。這時我們通常會取log讓預測值的分佈散開。實際上、當我們將Sale Price的分佈對做擬合會發現它的分布其實很接近log normal distribution (即取log 後成常態分佈)
y = train['SalePrice']
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=stats.norm)
plt.figure(3); plt.title('Log Normal')
sns.distplot(y, kde=False, fit=stats.lognorm)trainresult=np.log(data['SalePrice'])
繪製numerical_feature和Sale_Price的熱力圖觀察feature間的相關性大小:
plt.figure(figsize=(16, 16))
front=front.drop('Id',axis=1)
front['SalePrice']=np.log(train['SalePrice'])
corr = front.corr()
sns.heatmap(corr,cmap="viridis")
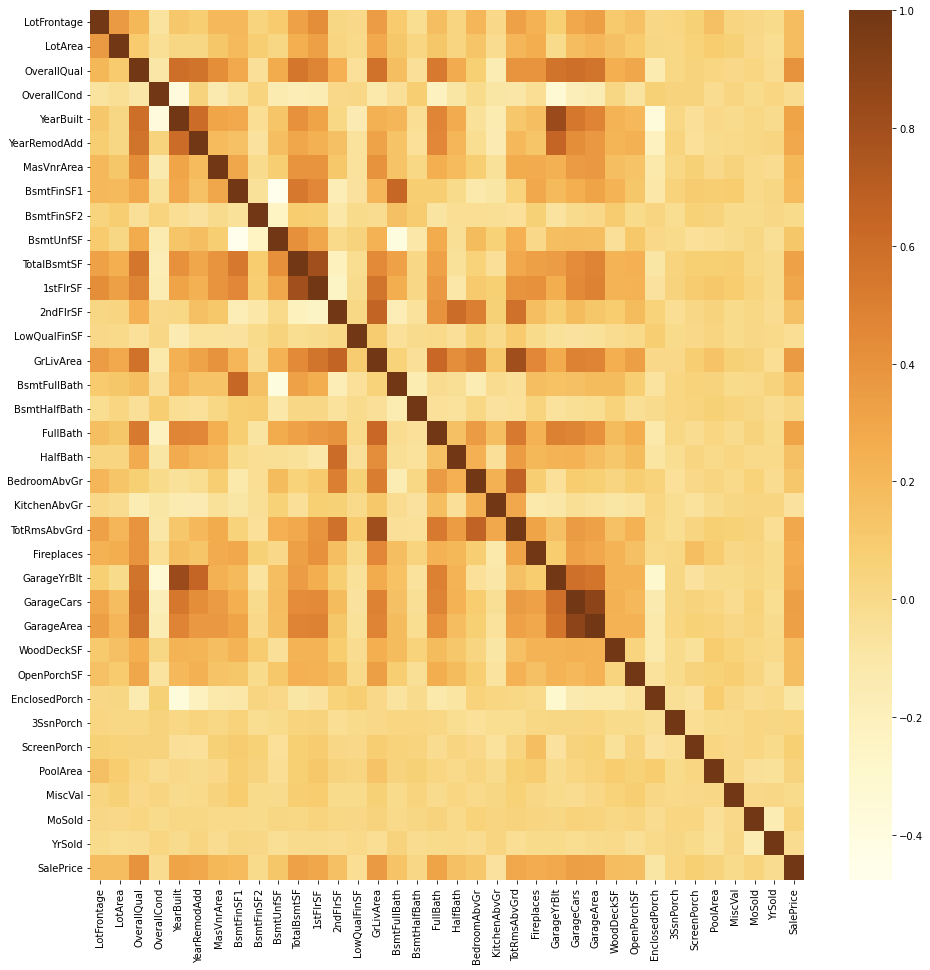
由上圖可看出TotalBsmt和1stFLSF,garage_area和garage_car有強烈關聯性,依據常理推斷是因為地下室總面積和第一層樓的面積大多數情況應是相同的,而garage面積愈大garage_car也會愈多
另外’OverallQual’ , ‘GrLivArea’和’Sale_Price’ 相關性比較大,可推測’OverallQual’ , ‘GrLivArea’會是training過程中權重較大的重要feature
至於看起來不太重要的feature(整列顏色都很黯淡)有:
‘BsmtFinSF2’, ‘LowQualFinSF’, ‘BsmtHalfBath’, ‘KitchenAbvGr’, ‘EnclosedPorch’, ‘3SsnPorch’, ‘ScreenPorch’, ‘PoolArea’, ‘MiscVal等等
而以上提及的這些不重要的feature正是前面提到『分佈非常集中且單一』的feature
另外也可看出’MoSold’ ‘YrSold’不太重要,可見銷售時間對房價沒有太大影響
接著對’object_type’ feature做one-hot coding,並將’object_type’和’numerical_type’ feature
重新組回單一dataframe,之後剔除根據data_visualization的結果判定不重要的feature
除此之外,某些’object_type’ feature中標示為None的對象是重複的,比如同筆交易資料顯示房子無Garage,則該筆資料中’GarageCond’, ‘GarageQual’, ‘GarageFinish’, ‘GarageType’通通都會是’None’,而經過one-hot coding處理後會產生’GarageCond_None’, ‘GarageQual_None’, ‘GarageFinish_None’ , ‘GarageType_None’等feature,此時這筆資料在這些feature中值通通都是1因;若該筆交易資料的房子有Garage則為零,即這些feature的值完全相同。因此我們只要保留一個feature即可
backw=pd.get_dummies(backw)
databass=pd.concat([front,backw],axis=1)
delete_feature=['MoSold', 'YrSold','Id','BsmtHalfBath',
'KitchenAbvGr', 'EnclosedPorch', '3SsnPorch', 'ScreenPorch',
'PoolArea', 'MiscVal','1stFlrSF','GarageArea','LowQualFinSF',
'BsmtFinSF2','GarageYrBlt']
repeatnon=[ 'GarageCond_None','GarageQual_None', 'GarageFinish_None', 'GarageType_None', 'BsmtCond_None','BsmtExposure_None',
'BsmtQual_None', 'BsmtFinType1_None', 'BsmtFinType2_None','MasVnrType_None']
databass=databass.drop(delete_feature,axis=1)
databass=databass.drop(repeatnon,axis=1)
‘numerical_type_feature’對Sale-Price的scatter plot
def scatter(x,y,**kwargs):
sns.scatterplot(x,y)
c= [f for f in database.columns if database.dtypes[f] != 'object']
c.remove('Id')
front['SalePrice']=train['SalePrice']
f = pd.melt(front, id_vars=['SalePrice'],value_vars=c)
g = sns.FacetGrid(f, col="variable", col_wrap=4 , sharex=False, sharey=False)
g = g.map(scatter, "value",'SalePrice')
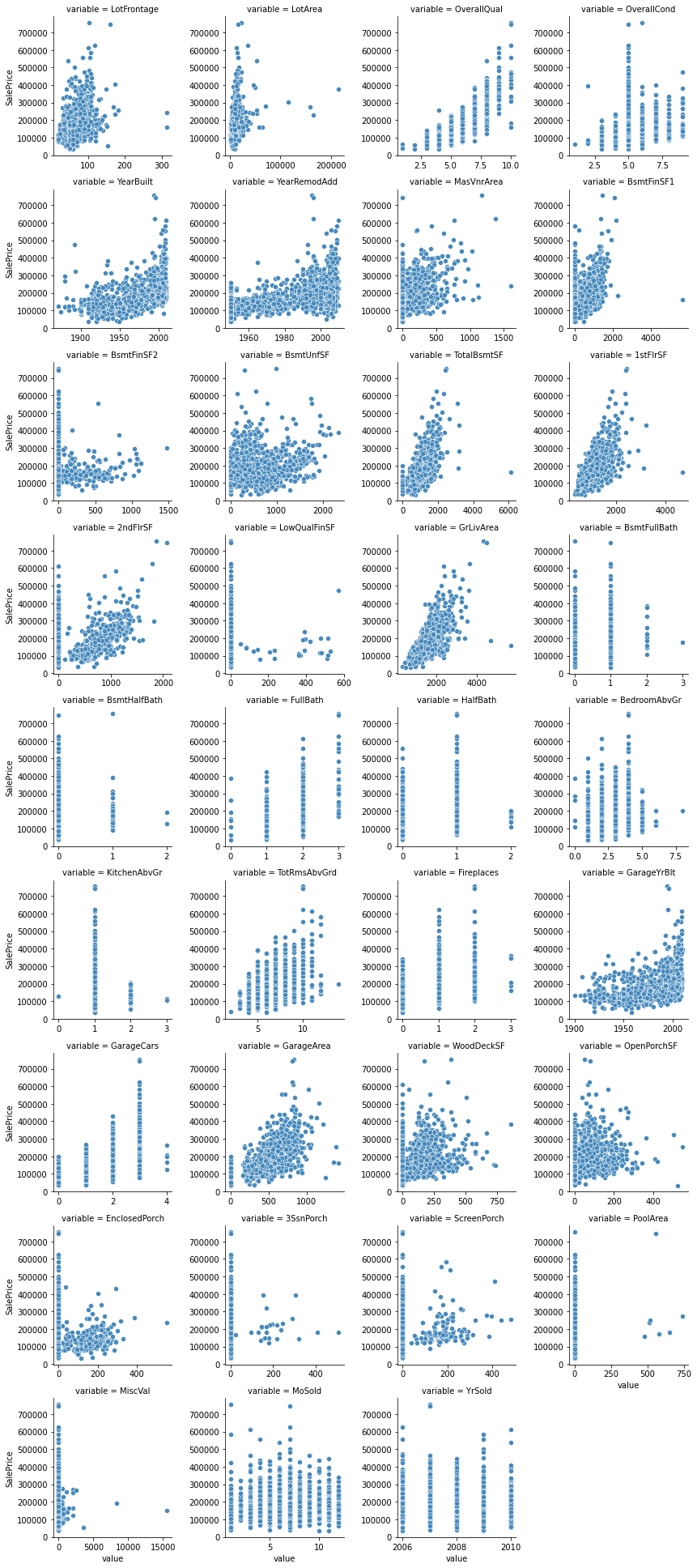
從上面這些圖來看,觀察前文分析出來可能較重要的feature: ‘OverallQual’ , ‘GrLivArea’,可發現在’OverallQual’最大的情況下有兩個點SalePrice偏低, 同樣的情況也可見於’GrLivArea’,這兩個點index為523及1298,明顯不符常理和其他點的趨勢,為異常值應去除
用Lasso選取重要feature:
Lasso是一種透過加入一次懲罰係數做regularization的線性模型,而在經過training後不重要的feature係數會變成零,是常被用來做feature selection的方式。並且,在training同時可以透過GridSearchCV的方式去找最合適的懲罰項係數,讓train出來最準確的模型判斷feature的重要性,留下權重大於0的項
#feature_selection by Lasso()
pipeline = Pipeline([('scaler',StandardScaler()),('model',Lasso())])
search = GridSearchCV(pipeline,{'model__alpha':np.arange(1e-3,1e-2,1e-4)},
cv = 5, scoring="neg_mean_squared_error",verbose=5)
search.fit(databass.iloc[:1458], trainresult)
print(search.best_params_)
coefficients = search.best_estimator_.named_steps['model'].coef_
importance = np.abs(coefficients)
feature=databass.columns
evaluate=pd.DataFrame({'feature':feature,'importance':importance})
drop=evaluate[evaluate['importance']==0]
databass=databass.drop(drop['feature'],axis=1)
Training Process:
在training process 中,我一共用了四個線性模型(Ridge, Lasso, Elastic Net, SVM Regressor)和兩個Boosting模型(Gradient Boosting, XGB)以及以前述六個模型當作第一階段的regressor,XGB演算法做第二階段的meta regressor做stacking,然後將stacking的模型和其他模型一起做blending
重新將training和testing data分開,定義cv_rmse_function為接下來評估各model使用的方法-10-fold cross validation做準備
trainfeature=databass[:1458] #2 outlier removed
testfeature=databass[1458:]
#define functions in training process
kfolds = KFold(n_splits=10, shuffle=True, random_state=42)def cv_rmse(model, X, y):
rmse = np.sqrt(-cross_val_score(model, X, y, scoring="neg_mean_squared_error",
cv=kfolds))
return (rmse)
設定六種模型的參數值,在linear model上使用RobustScaler()減少離群值對training process的影響及stacking的方式(first stage regressor=ridge, lasso, elasticnet,svr, gbr, xgbr, meta regressor= XGB)
alphas_alt = np.arange(14,16,0.1)
alphas2 = [0.003, 0.004, 0.005]
e_alphas = np.arange(1e-4,1e-3,1e-4)
e_l1ratio = np.arange(0.8,1,0.25)ridge = make_pipeline(RobustScaler(), RidgeCV(alphas=alphas_alt, cv=kfolds))
lasso = make_pipeline(RobustScaler(), LassoCV(max_iter=1e7, alphas=alphas2, random_state=42, cv=kfolds))
elasticnet = make_pipeline(RobustScaler(), ElasticNetCV(max_iter=1e7, alphas=e_alphas, cv=kfolds, l1_ratio=e_l1ratio))
svr = make_pipeline(RobustScaler(), SVR(C= 20, epsilon= 0.008, gamma=0.0003,))
xgbr= xgb.XGBRegressor(learning_rate= 0.01, max_depth= 3, n_estimators= 2500,objective='reg:linear')
gbr = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05, max_depth=4,
max_features='sqrt', min_samples_leaf=15, min_samples_split=10, loss='huber',
random_state =42)
stackr = StackingCVRegressor(regressors=(ridge, lasso, elasticnet,svr, gbr, xgbr),
meta_regressor=xgbr,use_features_in_secondary=True)
分別得到六個模型在training data set上的10-fold cross validation error,並記錄下來,當作後面做blending比例的參考
s=[]
score = cv_rmse(ridge,trainfeature, trainresult)
s.append(1/score.mean())
print("Ridge: {:.4f} ({:.4f})\\n".format(score.mean(), score.std()) )
score = cv_rmse(lasso,trainfeature, trainresult)
s.append(1/score.mean())
print("LASSO: {:.4f} ({:.4f})\\n".format(score.mean(), score.std()))
score = cv_rmse(elasticnet,trainfeature, trainresult)
print("elastic net: {:.4f} ({:.4f})\\n".format(score.mean(), score.std()) )
s.append(1/score.mean())
score = cv_rmse(svr,trainfeature, trainresult)
print("SVR: {:.4f} ({:.4f})\\n".format(score.mean(), score.std()))
s.append(1/score.mean())
score = cv_rmse(xgbr,trainfeature, trainresult)
print("xgboost: {:.4f} ({:.4f})\\n".format(score.mean(), score.std()))
s.append(1/score.mean())
score = cv_rmse(gbr,trainfeature, trainresult)
print("gboost: {:.4f} ({:.4f})\\n".format(score.mean(), score.std()))
s.append(1/score.mean())
讓七個模型各自做training
lasso_mod= lasso.fit(trainfeature, trainresult)
ridge_mod= ridge.fit(trainfeature, trainresult)
elasticnet_mod= elasticnet.fit(trainfeature, trainresult)
svr_mod = svr.fit(trainfeature, trainresult)
xgb_mod= xgbr.fit(trainfeature, trainresult)
gbr_mod= gbr.fit(trainfeature, trainresult)
stack_mod= stackr.fit(np.array(trainfeature), np.array(trainresult))
以六個模型(Ridge, Lasso, Elastic Net, SVM Regressor)依據各自的10-fold cross validation error的倒數做加總(註:為使error愈大的模型權重排名愈小,error愈小權重愈大),最後再與Stacking的模型做平均得到最終predict的結果
#blending
s=(s/np.sum(s))
def blend_predict(X):
return np.exp(0.5*((s[0] * ridge_mod.predict(X))+ (s[1] * lasso_mod.predict(X)) +
(s[2] * elasticnet_mod.predict(X)) + (s[3] * svr_mod.predict(X)) +
(s[4] * xgb_mod.predict(X))+(s[5] * gbr_mod.predict(X)))+0.5*stack_mod.predict(np.array(X))) testresult=blend_predict(testfeature)
最後predict結果的public score大約是0.1243(score的計算方式為將預測值和實際值取log後計算mean square error,這樣取log後算error的好處是error值不會受房價本身大小的影響,因此可以用來衡量不同數量級房價預測的準確性)